Quickstart¶
Dask-Yarn is designed to be used like any other python library - install it locally and use it in your code (either interactively, or as part of an application). As long as the computer you’re deploying on has access to the YARN cluster (usually an edge node), everything should work fine.
Install Dask-Yarn on an Edge Node¶
Dask-Yarn is designed to be used from an edge node. To install, use either
conda or pip to create a new environment and install dask-yarn on
the edge node.
Conda Environments:
Create a new conda environment with dask-yarn installed. You may also want
to add any other packages you rely on for your work.
$ conda create -n my_env dask-yarn # Create an environment
$ conda activate my_env # Activate the environment
Virtual Environments:
Create a new virtual environment with dask-yarn installed. You may also
want to add any other packages you rely on for your work.
$ python -m venv my_env # Create an environment using venv
$ source my_env/bin/activate # Activate the environment
$ pip install dask-yarn # Install some packages
Package your environment for Distribution¶
We need to ensure that the libraries used on the Yarn cluster are the same as
what you are using locally. By default, dask-yarn handles this by
distributing a packaged python environment to the Yarn cluster as part of the
applications. This is typically handled using
- conda-pack for Conda environments
- venv-pack for virtual environments
See Managing Python Environments for more information.
Conda Environments:
If you haven’t already installed conda-pack, you’ll need to do so now. You can either install it in the environment to be packaged, or your root environment (where it will be available to use in all environments).
$ conda install -c conda-forge conda-pack # Install conda-pack
$ conda-pack # Package environment
Collecting packages...
Packing environment at '/home/username/miniconda/envs/my_env' to 'my_env.tar.gz'
[########################################] | 100% Completed | 12.2s
Virtual Environments:
If you haven’t already installed venv-pack, you’ll need to do so now.
$ pip install venv-pack # Install venv-pack
$ venv-pack # Package environment
Collecting packages...
Packing environment at '/home/username/my-env' to 'my-env.tar.gz'
[########################################] | 100% Completed | 8.3s
Kinit (Optional)¶
If your cluster is configured to use Kerberos for authentication, you need to make sure you have an active ticket-granting-ticket before continuing:
$ kinit
Usage¶
To start a YARN cluster, create an instance of YarnCluster. This
constructor takes several parameters, leave them empty to use the defaults
defined in the Configuration.
from dask_yarn import YarnCluster
from dask.distributed import Client
# Create a cluster where each worker has two cores and eight GiB of memory
cluster = YarnCluster(environment='environment.tar.gz',
worker_vcores=2,
worker_memory="8GiB")
# Connect to the cluster
client = Client(cluster)
# Do some work here
# Shutdown client and cluster (alternatively use context-manager as shown below):
client.shutdown()
cluster.shutdown()
By default no workers are started on cluster creation. To change the number of
workers, use the YarnCluster.scale() method. When scaling up, new workers
will be requested from YARN. When scaling down, workers will be intelligently
selected and scaled down gracefully, freeing up resources.
# Scale up to 10 workers
cluster.scale(10)
# ...
# Scale back down to 2 workers
cluster.scale(2)
Alternatively, you can enable adaptive scaling using the
YarnCluster.adapt() method. When enabled, the cluster will scale up and
down automatically depending on usage. Here we turn on adaptive scaling,
bounded at a minimum of 2 workers and a maximum of 10 workers.
# Adaptively scale between 2 and 10 workers
cluster.adapt(minimum=2, maximum=10)
If you’re working interactively in a Jupyter Notebook or JupyterLab, you
can also use the provided graphical interface to change the cluster size,
instead of calling YarnCluster.scale() or YarnCluster.adapt()
manually.
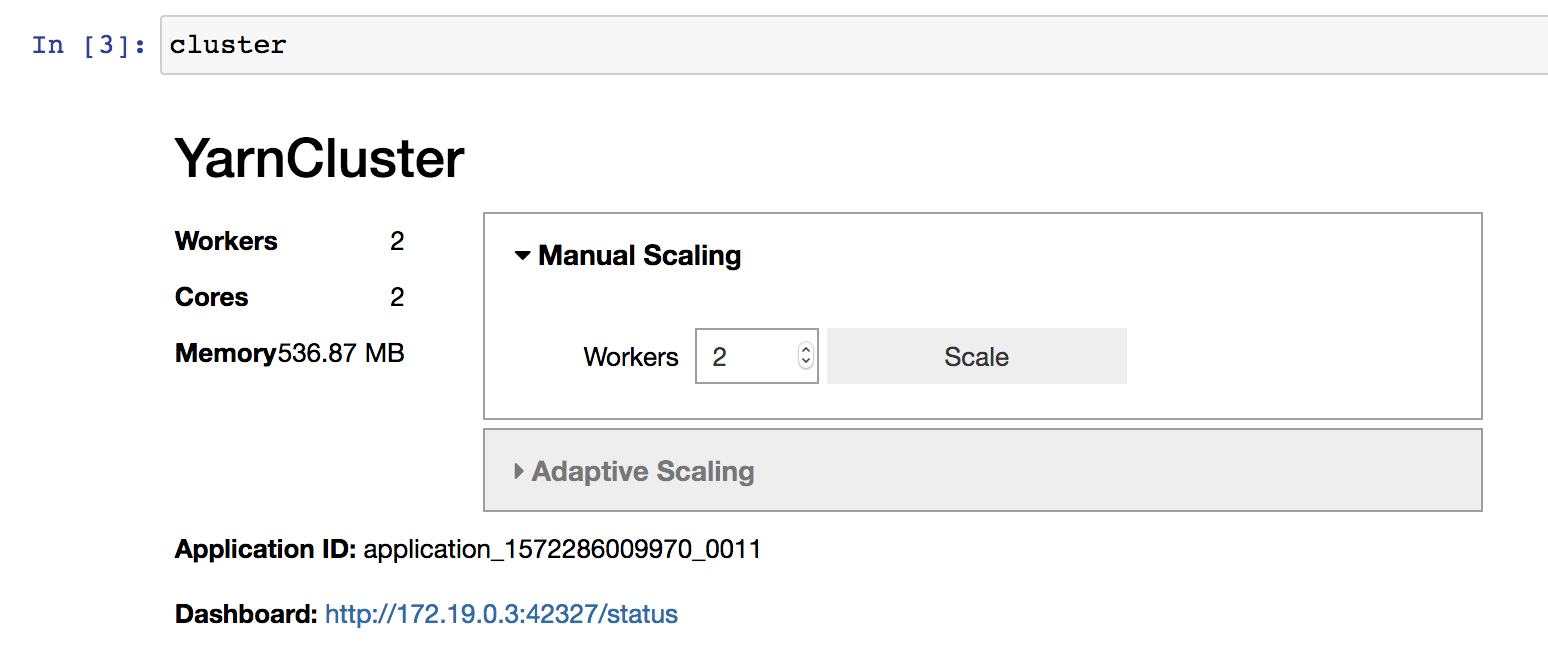
Normally the cluster will persist until the YarnCluster object is deleted.
To be more explicit about when the cluster is shutdown, you can either use the
cluster as a context manager, or manually call YarnCluster.shutdown().
# Use ``YarnCluster`` as a context manager
with YarnCluster(...) as cluster:
# The cluster will remain active inside this block,
# and will be shutdown when the context exits.
# Or manually call `shutdown`
cluster = YarnCluster(...)
# ...
cluster.shutdown()